Yesterday, David Benjamin posted a pretty esoteric note on the IETF’s TLS mailing list.  At a superficial level, the post describes some seizure-inducingly boring flaws in older Canon printers. To most people that was a complete snooze. To me and some of my colleagues, however, it was like that scene in X-Files where Mulder and Scully finally learn that aliens are real.
At a superficial level, the post describes some seizure-inducingly boring flaws in older Canon printers. To most people that was a complete snooze. To me and some of my colleagues, however, it was like that scene in X-Files where Mulder and Scully finally learn that aliens are real.
Those fossilized printers confirmed a theory we’d developed in 2014, but had been unable to prove: namely, the existence of a specific feature in RSA’s BSAFE TLS library called “Extended Random” — one that we believe to be evidence of a concerted effort by the NSA to backdoor U.S. cryptographic technology.
Before I get to the details, I want to caveat this post in two different ways. First, I’ve written about the topic of cryptographic backdoors way too much. In 2013, the Snowden revelations revealed the existence of a campaign to sabotage U.S. encryption systems. Since that time, cryptographers have spent thousands of hours identifying, documenting, and trying to convince people to care about these backdoors. We’re tired and we want to do more useful things.
The second caveat covers a problem with any discussion of cryptographic backdoors. Specifically, you never really get absolute proof. There’s always some innocent or coincidental explanation that could sort of fit the evidence — maybe it was all a stupid mistake. So you look for patterns of unlikely coincidences, and use Occam’s razor a lot. You don’t get a Snowden every day.
With all that said, let’s talk about Extended Random, and what this tells us about the NSA. First some background.
Dual_EC_DRBG and RSA BSAFE
To understand the context of this discovery, you need to know about a standard called Dual EC DRBG. This was a proposed random number generator that the NSA developed in the early 2000s. It was standardized by NIST in 2007, and later deployed in some important cryptographic products — though we didn’t know it at the time.
Dual EC has a major problem, which is that it likely contains a backdoor. This was pointed out in 2007 by Shumow and Ferguson, and effectively confirmed by the Snowden leaks in 2013. Drama ensued. NIST responded by pulling the standard. (For an explainer on the Dual EC backdoor, see here.)
Somewhere around this time the world learned that RSA Security had made Dual EC the default random number generator in their popular cryptographic library, which was called BSAFE. RSA hadn’t exactly kept this a secret, but it was such a bonkers thing to do that nobody (in the cryptographic community) had known. So for years RSA shipped their library with this crazy algorithm, which made its way into all sorts of commercial devices.
The RSA drama didn’t quite end there, however. In late 2013, Reuters reported that RSA had taken $10 million to backdoor their software. RSA sort of denies this. Or something. It’s not really clear.
Regardless of the intention, it’s known that RSA BSAFE did incorporate Dual EC. This could have been an innocent decision, of course, since Dual EC was a NIST standard. To shed some light on that question, in 2014 my colleagues and I decided to reverse-engineer the BSAFE library to see if it the alleged backdoor in Dual EC was actually exploitable by an attacker like the NSA. We figured that specific engineering decisions made by the library designers could be informative in tipping the scales one way or the other.
It turns out they were.
Extended Random
In the course of reverse engineering the Java version of BSAFE, we discovered a funny inclusion. Specifically, we found that BSAFE supports a non-standard extension to the TLS protocol called “Extended Random”.
The Extended Random extension is an IETF Draft proposed by an NSA employee named Margaret Salter (at some point the head of NSA’s Information Assurance Directorate, which worked on “defensive” crypto for DoD) along with Eric Rescorla as a contractor. (Eric was very clearly hired to develop a decent proposal that wouldn’t hurt TLS, and would primarily be used on government machines. The NSA did not share their motivations with him.)
It’s important to note that Extended Random by itself does not introduce any cryptographic vulnerabilities. All it does is increase the amount of random data (“nonces”) used in a TLS protocol connection. This shouldn’t hurt TLS at all, and besides it was largely intended for U.S. government machines.
The only thing that’s interesting about Extended Random is what happens when that random data is generated using the Dual EC algorithm. Specifically, this extra data acts as “rocket fuel”, significantly increasing the efficiency of exploiting the Dual EC backdoor to decrypt TLS connections.
In short, if you’re an agency like the NSA that’s trying to use Dual EC as a backdoor to intercept communications, you’re much better off with a system that uses both Dual EC DRBG and Extended Random. Since Extended Random was never standardized by the IETF, it shouldn’t be in any systems. In fact, to the best of our knowledge, BSAFE is the only system in the world that implements it.
In addition to Extended Random, we discovered a variety of features that, combined with the Dual EC backdoor, could make RSA BSAFE fairly easy to exploit. But Extended Random is by far the strangest and hardest to justify.
So where did this standard come from? For those who like technical mysteries, it turns out that Extended Random isn’t the only funny-smelling proposal the NSA made. It’s actually one of four failed IETF proposals made by NSA employees, or contractors who work closely with the NSA, all of which try to boost the amount of randomness in TLS. Thomas Ptacek has a mind-numbingly detailed discussion of these proposals and his view of their motivation in this post.
Oh my god I never thought spies could be so boring. What’s the new development?
Despite the fact that we found Extended Random in RSA BSAFE (a free version we downloaded from the Internet), a fly in the ointment was that it didn’t actually seem to be enabled. That is: the code was there but the switches to enable it were hard-coded to “off”.
This kind of put a wrench in our theory that RSA might have included Extended Random to make BSAFE connections more exploitable by the NSA. There might be some commercial version of BSAFE out there with this code active, but we were never able to find it or prove it existed. And even worse, it might appear only in some special “U.S. government only” version of BSAFE, which would tend to undermine the theory that there was something intentional about including this code — after all, why would the government spy on itself?
Which finally brings us to the news that appeared on the TLS mailing list the other day. It turns out that certain Canon printers are failing to respond properly to connections made using the new version of TLS (which is called 1.3), because they seem to have implemented an unauthorized TLS extension using the same number as an extension that TLS 1.3 needs in order to operate correctly. Here’s the relevant section of David’s post:
The web interface on some Canon printers breaks with 1.3-capable
ClientHello messages. We have purchased one and confirmed this with a
PIXMA MX492. User reports suggest that it also affects PIXMA MG3650
and MX495 models. It potentially affects a wide range of Canon
printers.
These printers use the RSA BSAFE library to implement TLS and this
library implements the extended_random extension and assigns it number
40. This collides with the key_share extension and causes 1.3-capable
handshakes to fail.
So in short, this news appears to demonstrate that commercial (non-free) versions of RSA BSAFE did deploy the Extended Random extension, and made it active within third-party commercial products. Moreover, they deployed it specifically to machines — specifically off-the-shelf commercial printers — that don’t seem to be reserved for any kind of special government use.
(If these turn out to be special Department of Defense printers, I will eat my words.)
Ironically, the printers are now the only thing that still exhibits the features of this (now deprecated) version of BSAFE. This is not because the NSA was targeting printers. Whatever devices they were targeting are probably gone by now. It’s because printer firmware tends to be obsolete and yet highly persistent. It’s like a remote pool buried beneath the arctic circle that preserves software species that would otherwise vanish from the Internet.
Which brings us to the moral of the story: not only are cryptographic backdoors a terrible idea, but they totally screw up the assigned numbering system for future versions of your protocol.
Actually no, that’s a pretty useless moral. Instead, let’s just say that you can deploy a cryptographic backdoor, but it’s awfully hard to control where it will end up.






 Dual EC random number generator as the default in their flagship BSAFE library. I’ve
Dual EC random number generator as the default in their flagship BSAFE library. I’ve 






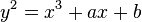 mod p. The values a and b are defined as part of the curve parameters.
mod p. The values a and b are defined as part of the curve parameters.









{kind=link}